반응형
"오늘날의 LLM은 똑똑합니다."
Anthropic 의 Skill Creator 의 SKILL.md 에 있는 문구입니다.
저는 최근 하네스 구성을 자동으로 해주는 Harness Skill 을 깍아내면서, 스킬이 좀 더 고도화되면 좋을텐데 하고 고민을 하던 차에 2주 전, Anthropic 이 공개한 Skill Creator 를 업데이트 한 내용을 살펴 보았습니다.
* Skill Creator : AI에게 새로운 능력(스킬)을 가르치는 도구
그 결과, Skill Creator의 진화는 작은 도구의 업데이트처럼 보이지만, 사실은 AI 산업 전체가 향하는 방향의 축소판이라는 것을 알게 되었습니다.

v1에서 v2로의 변화를 관통하는 하나의 문장이 있다면 이것입니다.
"사람이 AI를 사용하는 도구"에서 "AI가 스스로를 개선하되, 사람이 방향을 결정하는 시스템"으로.
이 전환이 의미하는 것은 분명합니다.
개발자에게는 프롬프트를 잘 쓰는 기술보다 평가를 잘 설계하는 기술이 중요해집니다. 기업에게는 AI 도입이 "도구 구매"가 아니라 "평가 체계 구축"이 됩니다. 어떤 모델을 쓰느냐보다 어떻게 측정하느냐가 더 중요해집니다. 그리고 사내에 축적되는 스킬과 에이전트가 무형 자산이 됩니다.
AI 업계에게는 "더 큰 모델"보다 "더 나은 자기 개선 루프"가 경쟁 우위가 됩니다. Anthropic이 v2에서 보여준 것은 모델 크기의 승리가 아니라 시스템 설계의 승리입니다. 평가하고, 분석하고, 개선하는 순환 구조를 얼마나 잘 설계하느냐가 최종 산출물의 품질을 결정합니다.
그렇다면 어떤 변화들이 있었는지 살펴보겠습니다.
1️⃣ 매뉴얼을 버리고 실험실을 차렸습니다.
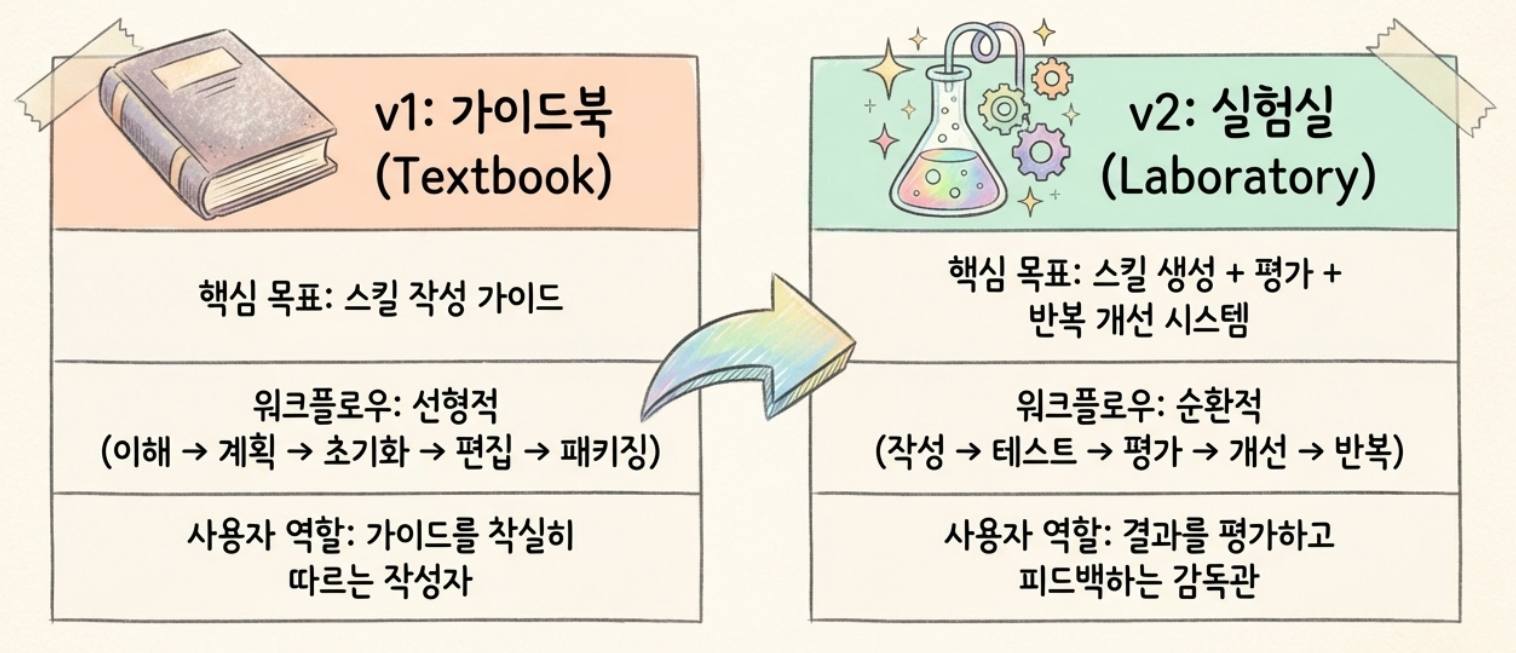
v1은 교과서였습니다. "스킬을 이렇게 쓰세요"라는 가이드라인이 잘 정리되어 있었고, 템플릿 생성기로 빈 껍데기를 만들어주고, 사람이 내용을 채우고, 검증하고, 패키징하는 순서를 따랐습니다. 나쁘지 않은 접근입니다. 하지만 여기서 사람은 작성자이고, AI는 실행자였습니다.
v2는 실험실이 되었습니다. 스킬을 작성하는 것까지는 같지만, 그 다음이 완전히 다릅니다. AI가 자동으로 테스트를 만들고, 여러 버전을 병렬로 돌려보고, 결과를 채점하고, 통계를 내고, 시각화해서 사람에게 보여줍니다. 사람이 "이건 좋고, 저건 별로야"라고 피드백하면, AI가 그걸 반영해서 스킬을 고치고 다시 테스트합니다. 이 루프를 사람이 만족할 때까지 반복합니다.
한마디로, 사람이 직접 요리하던 주방에서 AI 셰프가 요리하고 사람은 시식만 하는 구조로 바뀐 것입니다.
2️⃣ Claude가 Claude를 가르칩니다.
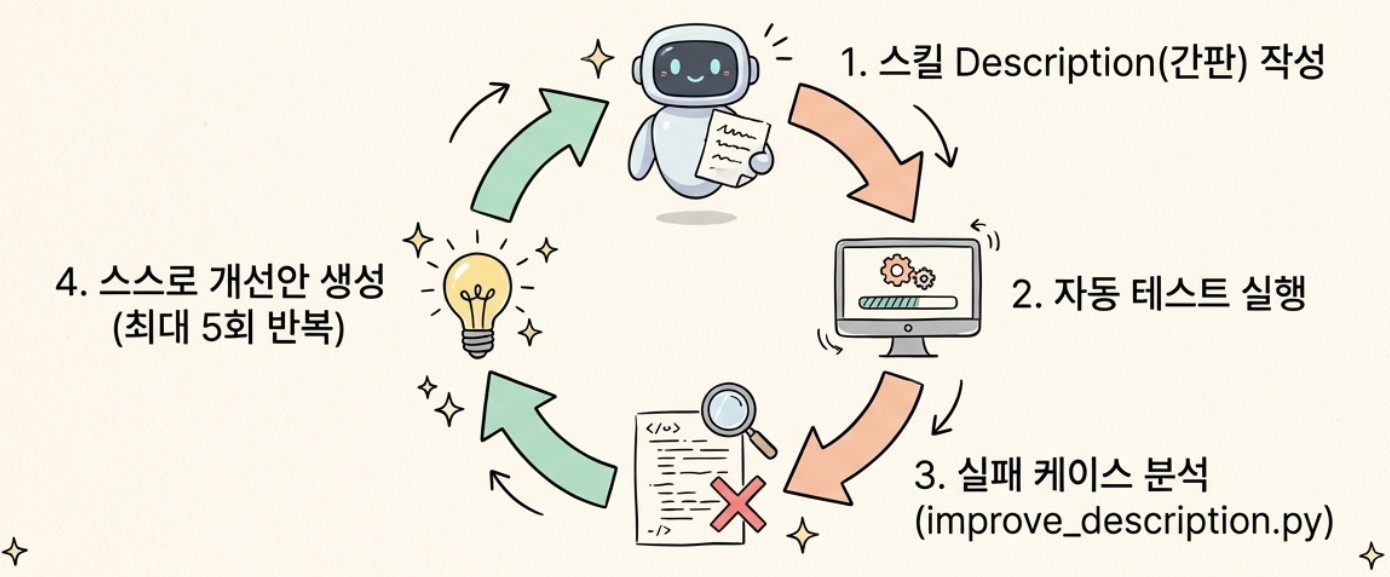
v2에서 가장 눈에 띄는 건 description 자동 최적화 기능입니다. 스킬의 description이란 일종의 간판입니다. 사용자가 무언가를 요청했을 때, Claude가 "이 스킬을 쓸까 말까"를 판단하는 기준이 됩니다. 간판이 애매하면 필요할 때 안 쓰고, 너무 넓으면 필요 없을 때도 씁니다.
v1에서는 사람이 이 간판을 직접 썼습니다. "잘 써보세요"라는 가이드와 함께.
v2에서는 이렇게 바뀌었습니다. 먼저 "이런 질문이 들어오면 이 스킬이 작동해야 한다"는 테스트 케이스 20개를 만듭니다. 그 중 12개로 훈련하고 8개로 검증합니다. Claude가 현재 description으로 테스트를 돌리고, 실패한 케이스를 분석해서, 더 나은 description을 스스로 작성합니다. 다시 테스트하고, 다시 고치고, 최대 5번까지 반복합니다. 마지막에 검증용 8개에서 가장 높은 점수를 받은 description을 채택합니다.
이건 머신러닝에서 쓰는 train/test split 기법과 동일한 구조입니다. 과적합(overfitting)을 방지하기 위해 훈련 데이터와 검증 데이터를 분리하고, 검증 데이터 기준으로 최적을 선택합니다. 다만 여기서 최적화되는 대상이 모델의 가중치가 아니라 프롬프트라는 점이 다를 뿐입니다.
Anthropic이 이걸 사용자 대면 제품에 넣었다는 건 중요한 신호입니다. 이들은 "프롬프트를 잘 쓰는 기술"이 아니라 "평가 기준을 잘 설계하는 기술"이 앞으로의 핵심이라고 보고 있습니다. 프롬프트는 AI가 알아서 최적화할 수 있지만, "이 AI가 잘하고 있는지 아닌지"를 판단하는 기준은 사람만이 정의할 수 있으니까요.
3️⃣ 혼자 똑똑한 AI보다 팀으로 움직이는 AI
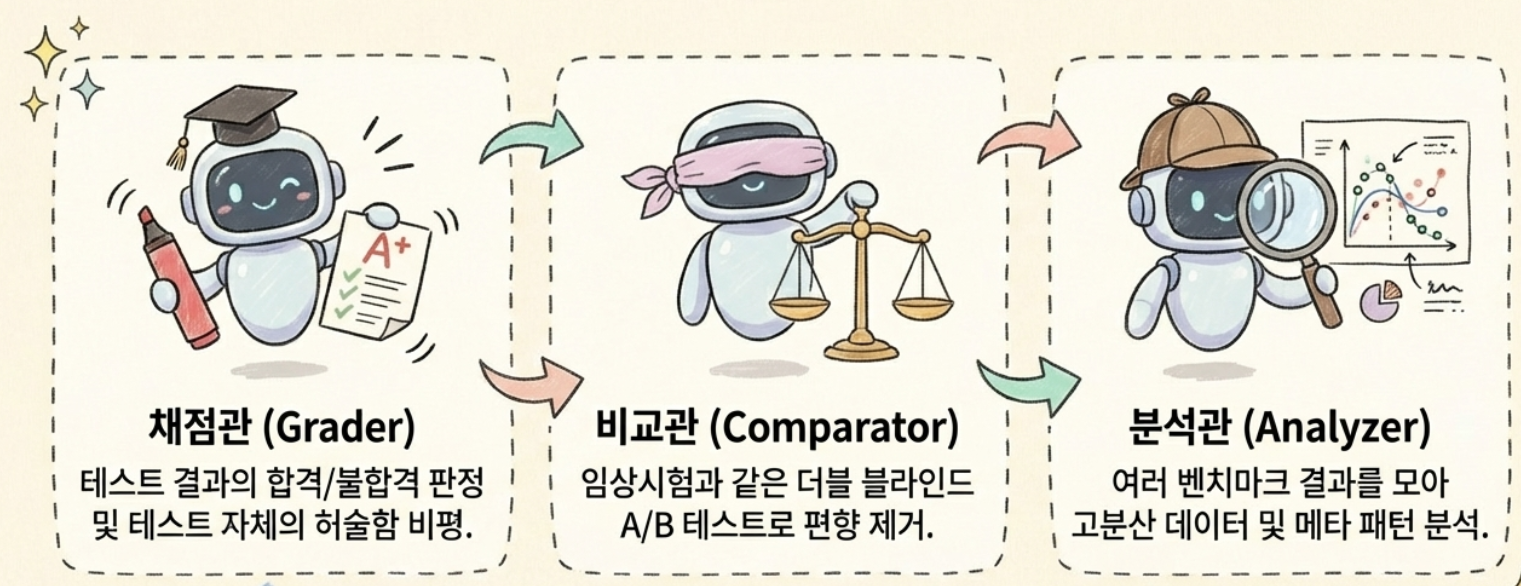
v1에는 에이전트라는 개념 자체가 없었습니다. 하나의 Claude가 모든 걸 했습니다. v2에는 세 명의 전문가가 등장합니다.
- 채점관(Grader)은 테스트 결과를 보고 합격/불합격을 판정합니다. 단순히 "맞다/틀리다"만 보는 게 아니라, "이 테스트 자체가 허술한 건 아닌지"까지 비평합니다. 파일 이름만 맞으면 통과하는 테스트가 있다면, "내용은 확인 안 하는데 괜찮겠습니까"라고 지적합니다.
- 비교관(Comparator)은 블라인드 테스트를 수행합니다. 두 개의 결과물을 A와 B로만 표시하고, 어떤 스킬이 만든 건지 모르는 상태에서 품질을 비교합니다. 임상시험에서 쓰는 이중맹검법과 같은 원리입니다. 자기가 만든 걸 자기가 평가하면 편향이 생기니까요.
- 분석관(Analyzer)은 여러 차례의 벤치마크 결과에서 패턴을 찾습니다. "이 테스트는 스킬이 있든 없든 항상 통과하니까 변별력이 없습니다", "3번 테스트는 결과가 들쭉날쭉하니까 신뢰하기 어렵습니다" 같은 메타 분석을 제공합니다.
이 구조가 흥미로운 이유는, 소프트웨어 업계가 10년 전에 겪은 전환과 똑같기 때문입니다. 모놀리식 애플리케이션에서 마이크로서비스로 넘어간 것처럼, AI도 하나의 만능 모델에서 역할이 분리된 전문가 에이전트의 협업으로 넘어가고 있습니다. 그리고 이 전환의 핵심 이유도 같습니다 — "관심사의 분리". 만든 사람이 채점하면 객관성이 떨어지고, 한 에이전트가 모든 맥락을 안고 있으면 컨텍스트가 오염됩니다.
4️⃣ 사람의 자리가 바뀌고 있습니다

v1에서 사람의 역할은 이랬습니다: 가이드를 읽습니다. 계획을 세웁니다. 스킬을 작성합니다. 테스트합니다. 고칩니다. 모든 단계의 주어가 "사람"입니다.
v2에서 사람의 역할은 이렇게 바뀌었습니다: AI가 작성합니다. AI가 테스트를 돌립니다. AI가 결과를 브라우저에 띄워줍니다. 사람이 결과를 보고 피드백합니다. AI가 피드백을 반영해서 고칩니다. 사람이 개입하는 지점은 딱 하나, 판단입니다.
이걸 업계에서는 "Human-in-the-Loop"에서 "Human-on-the-Loop"로의 전환이라고 부릅니다. 루프 안에서 매 단계마다 일하던 사람이, 루프 위에서 감독하는 위치로 올라간 것입니다. AI가 먼저 달리고, 사람은 방향이 맞는지 확인하고, 필요하면 조정합니다.
Anthropic이 만든 Eval Viewer가 이 철학을 잘 보여줍니다. 테스트 결과를 테이블이나 JSON으로 던지는 게 아니라, 브라우저에서 깔끔하게 시각화하고, 이전 버전과 나란히 비교할 수 있게 하고, 각 결과에 피드백을 쓸 수 있는 텍스트 박스를 달아놓았습니다. 사람이 가장 효율적으로 판단을 내릴 수 있도록 환경을 만들어주는 것입니다. 코드를 작성하는 데 사람의 시간을 쓰지 말고, 판단하는 데 쓰라는 메시지입니다.
5️⃣ "ALWAYS"라고 소리치지 마세요, 이유를 설명하세요.

v1의 스킬 작성 가이드에는 이런 문장들이 있었습니다. "ALWAYS use imperative form." "Keep under 500 lines." 명확하고 단호한 규칙입니다. AI에게 이렇게 하라, 저렇게 하지 마라고 지시하는 방식입니다.
v2는 정반대의 철학을 제시합니다. SKILL.md에 이런 문장이 있습니다.
"ALWAYS나 NEVER 같은 대문자로 쓴 지시를 자꾸 쓰고 있다면, 그건 경고 신호입니다. 가능하다면 그렇게 해야 하는 이유를 설명해서, 모델이 왜 그게 중요한지 이해하게 하세요. 그게 더 인간적이고, 강력하고, 효과적인 접근입니다."
그리고 바로 뒤에 이 문장이 옵니다.
"오늘날의 LLM은 똑똑합니다. 좋은 맥락이 주어지면 기계적인 지시를 넘어서 정말로 일을 해냅니다."
이건 단순한 작문 스타일의 변화가 아닙니다. Anthropic이 자사 모델에 대한 자신감을 드러내는 것입니다. v1 시점에는 "구체적 규칙이 없으면 Claude가 헤맬 수 있다"고 봤다면, v2 시점에는 "이유를 이해하면 Claude가 스스로 최적의 방법을 찾는다"고 보는 것입니다.
이 전환은 프롬프트 엔지니어링 전체에 대한 청사진이기도 합니다. 지금은 "이 단어를 넣으면 잘 되더라"식의 기법이 공유되지만, 모델이 계속 똑똑해지면 그런 트릭은 의미가 없어집니다. 대신 "무엇을 왜 원하는지"를 명확하게 전달하는 능력이 중요해집니다. 그리고 궁극적으로는 프롬프트조차 필요 없어지고, 평가 기준만 정의하면 AI가 알아서 최적의 프롬프트를 찾는 시대가 옵니다. v2의 description 최적화 기능이 바로 그 미래의 프로토타입입니다.
6️⃣ 개발자의 터미널이 AI 실험실이 됩니다.

v1에는 스크립트가 3개였습니다. 스킬 초기화, 검증, 패키징. 도구를 만드는 최소한의 유틸리티였습니다.
v2에는 8개의 스크립트와 웹 뷰어가 있습니다. 평가 실행, 결과 집계, description 개선, 벤치마크 리포트 생성, 최적화 루프, 리뷰 뷰어까지. 이건 도구 모음이 아니라 하나의 플랫폼입니다.
그리고 이 모든 것이 claude -p라는 CLI 명령어 하나를 축으로 돌아갑니다. claude -p는 Claude를 headless 모드로 실행하는 명령어입니다. GUI 없이, 프로그래밍 방식으로, 다른 스크립트 안에서 Claude를 호출할 수 있습니다. v2의 run_eval.py는 이걸 이용해서 테스트 케이스 20개를 동시에 돌립니다. improve_description.py는 이걸 이용해서 Claude에게 "이 description을 개선해줘"라고 요청합니다.
이건 gcc나 npm처럼 빌드 도구가 되는 것입니다. 개발자의 CI/CD 파이프라인에 claude -p가 들어가는 미래를 Anthropic이 설계하고 있습니다. 코드를 커밋하면 Claude가 자동으로 리뷰하고, 테스트를 생성하고, 문서를 업데이트하는 워크플로우. v2의 Skill Creator는 그 미래의 축소판입니다.
7️⃣ 하나의 스킬, 어디서든 작동합니다.

v1은 실행 환경에 대해 아무 말도 하지 않았습니다. v2는 세 가지 환경을 명시적으로 구분합니다.
Claude Code에서는 모든 기능을 쓸 수 있습니다. 서브 에이전트를 병렬로 돌리고, 브라우저에서 결과를 리뷰하고, description을 자동 최적화합니다. Claude.ai에서는 서브 에이전트가 없으니 순차적으로 실행하고, 브라우저 리뷰어 대신 대화 안에서 직접 결과를 보여줍니다. Cowork에서는 서브 에이전트는 있지만 브라우저가 없으니 HTML 파일을 생성해서 다운로드하게 합니다.
같은 스킬인데 환경에 따라 실행 방식을 알아서 바꿉니다. 이건 Java의 "Write once, run anywhere"를 떠올리게 합니다. .skill 파일 하나가 어떤 Claude 환경에서든 작동하는 포터블 AI 능력 패키지가 되는 것입니다.
이 방향이 계속되면 스킬은 npm 패키지 같은 것이 됩니다. 누군가가 "PDF 편집" 스킬을 만들어서 공유하면, 다른 사람이 설치해서 쓰고, 포크해서 자기 용도에 맞게 고치고, 버전 관리를 하고, 레지스트리에 등록합니다.
반응형
'AI > AI 도구' 카테고리의 다른 글
| Claude Code 내부 구조 완전 해부: Agent, Team, Skill 시스템의 비밀 (1) | 2026.04.03 |
|---|---|
| 누구나 쉽게 이해할 수 있는 MCP 가이드 (2) | 2025.03.30 |
| 차원이 다른 AI 번역: 더 똑똑해진 한글 자막 생성기를 소개합니다 (2) | 2024.09.14 |



