최근 마이크로소프트에서 "The Dawn of LMMs" 이란 제목의 논문을 발표했습니다.
여기서는 정량적 벤치마킹 대신 정성적 결과를 사용하여 GPT-4V의 새로운 기능과 잠재적인 새로운 사용 사례를 엿볼 수 있었습니다. 물론 아직까지는 완전히 신뢰할 수 없는 새로운 기능일지라도 GPT-4V가 이미 수행할 수 있는 기능을 발견하고 미리 살펴보데 의의를 두고 있다고 합니다.
이 논문에서는 세부 카테고리별로 프롬프트와 이미지를 통한 GPT-4V 의 결과를 소개하고 있으며, 무려 124개의 이미지 사례를 포함하고 있습니다. 여기서는 모든 사례를 소개할 수 없으므로 한번쯤은 해당 논문을 참고하여 살펴보시는 것을 권장드립니다.
https://arxiv.org/pdf/2309.17421.pdf
* PDF 논문을 html로 변환해주는 arxiv-vanity 사이트의 도움을 받으면 좀 더 수월하게 웹 번역하여 확인해볼 수 있습니다.
논문에 나와 있는 내용은 아래와 같습니다. (*논문의 목차와는 일치하지 않습니다)
멀티 모달 개념 이해 및 사용 방법
1. GPT-4V 입력모드 소개
2. GPT-4V 에서의 프롬프트 기법 소개
3. 상호작용을 통한 프롬프트 입력
4. 비전 언어에 대한 이해
5. 멀티 이미지 시퀀싱과 비디오에 대한 이해
<= 이 포스팅에서는 여기까지만 다룹니다.
테스트
6. 추상적 시각 추론 및 지능 지수 테스트
7. 사람의 표정에서 감정 읽기 등 감정 지수 테스트
발전 방향 및 가능성
8. 산업, 의료, 자동차 보험, 맞춤형 캡션, 이미지 생성, 에이전트, GUI 영역의 하이라이트
9. LMM 기반의 에이전트들 (멀티모달 플러그인, 멀티모달 체인, 자기성찰, 일관성, LMM 검색 증강)
1. GPT-4V 입력 모드
- GPT-4V 에서는 텍스트 입력 뿐만 아니라 한 개 이상의 이미지와 텍스트를 함께 입력할 수 있게 됩니다.

2. GPT-4V 프롬프트 기법
- 아래 예시는 이미지에서 정형화된 JSON 형식을 반환받는 예제 입니다. 단, 빨간색은 오답을 나타냅니다.

- 아래 예시는 이미지 속 사과 갯수를 세는 예시입니다. 이미지에는 11개의 사과가 있지만 상단 이미지가 잘려서 GPT-4V 는 12개 사과가 있다고 잘못 알려주고 있습니다. 이 경우, 프롬프트 수정만으로 11개로 올바르게 인식할 수 있을까요? 만능 키워드로 알려진 "Let's think step-by-step" 도 무용지물이네요.
그러나 놀랍게도 "여러분은 이미지 속 사물의 개수를 세는 전문가입니다. 아래 이미지에 있는 사과의 개수를 한 줄씩 세어 정답이 맞는지 확인해 봅시다." 이라고 프롬프트를 최종 수정하자 사과를 11개로 인식합니다.

3. 상호작용을 통한 프롬프트 입력
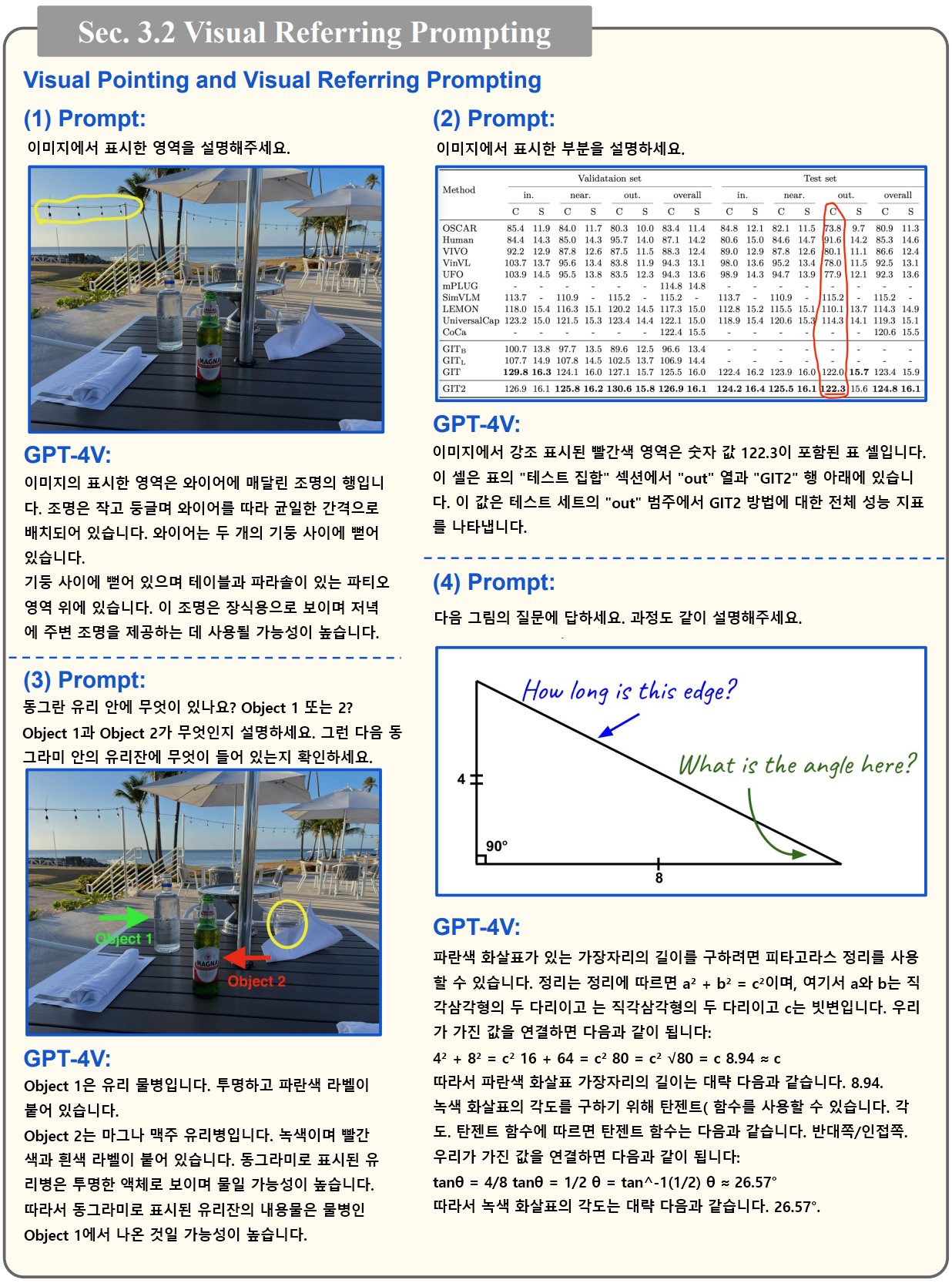
- Visual Pointing과 Visual Referring 방식을 통해서 프롬프트를 줄 수 있습니다.
- 아래 예시와 같이 기존 이미지에 표시를 하거나 참조 정보를 덮어 그려서 전달하면 그것을 이해하고 의도한대로 답변합니다.
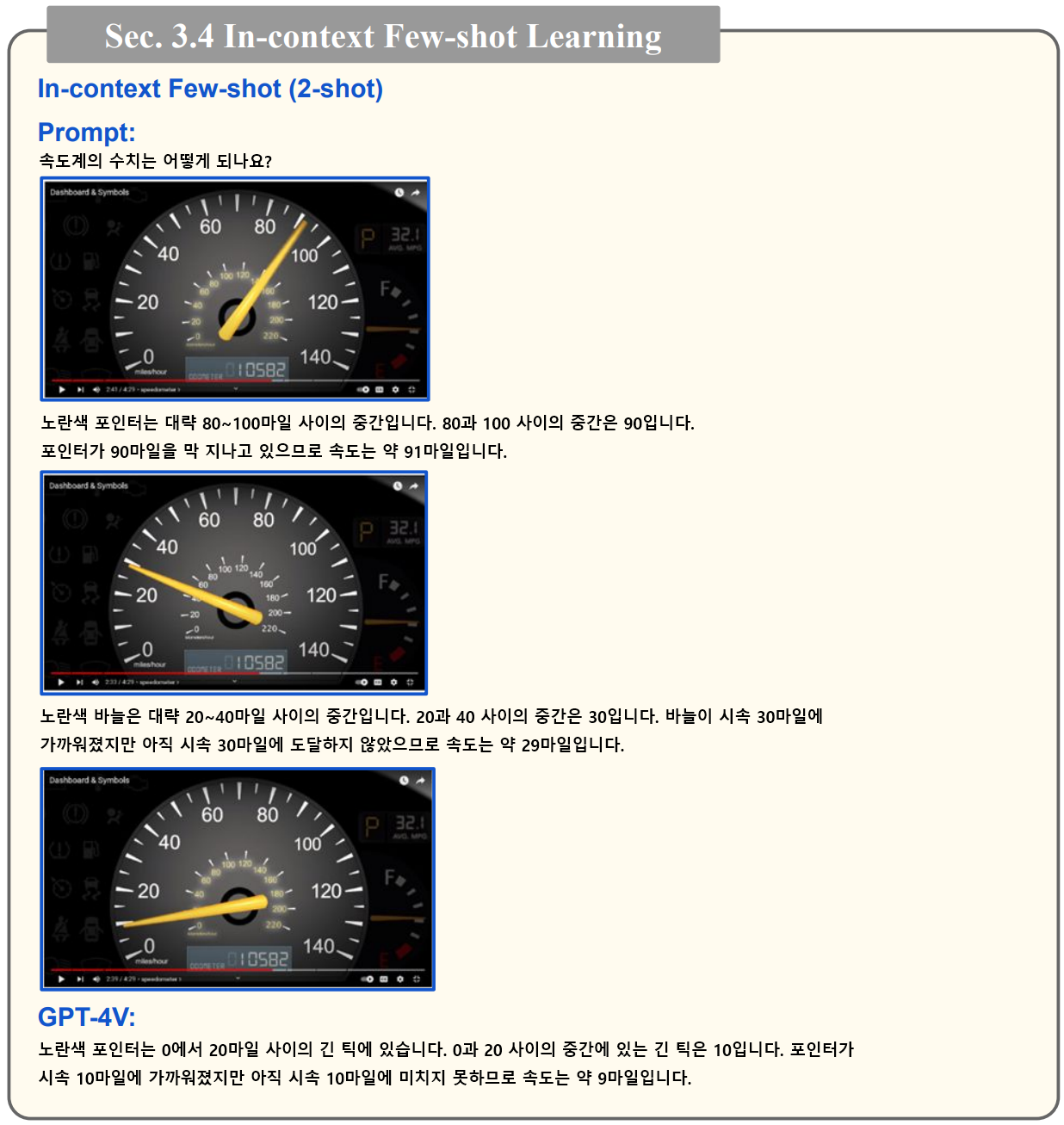
- 아래 예시는 계기판 이미지를 인식할 수 있는지에 대한 테스트입니다. 처음에는 계기판 이미지를 올바르게 인식하지 못합니다. 또한 이미지에 대한 설명을 추가해도 인식이 안되는 것으로 확인됩니다. 하지만 아래와 같이 90마일인 경우, 29마일인 경우 이렇게 몇 가지 예시를 추가로 제공함으로써 Few-shot Learning 이 가능하다고 합니다. 물론 모든 상황에 항상 가능한 것은 아니라고 하는군요.
4. 비전 언어에 대한 이해
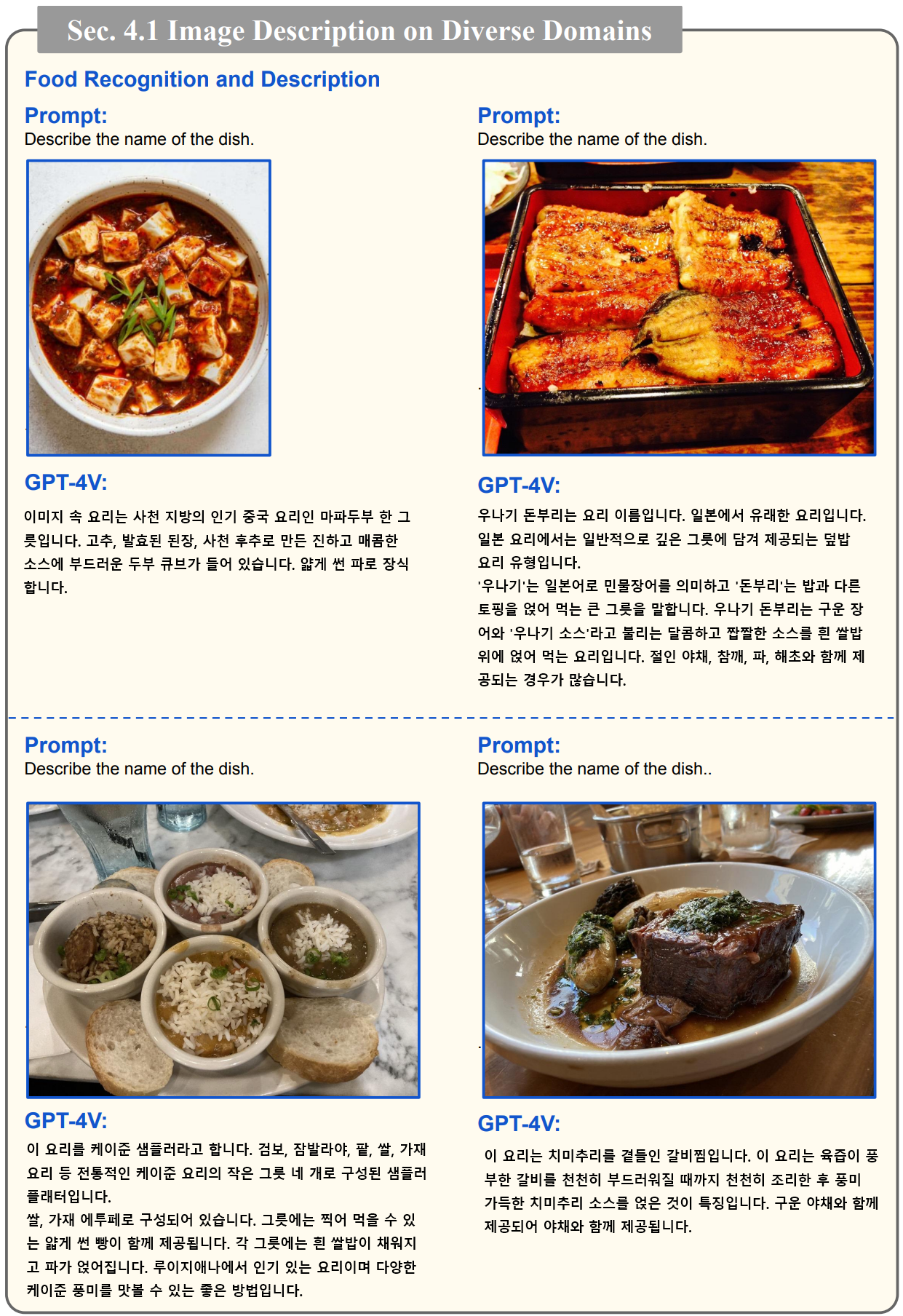
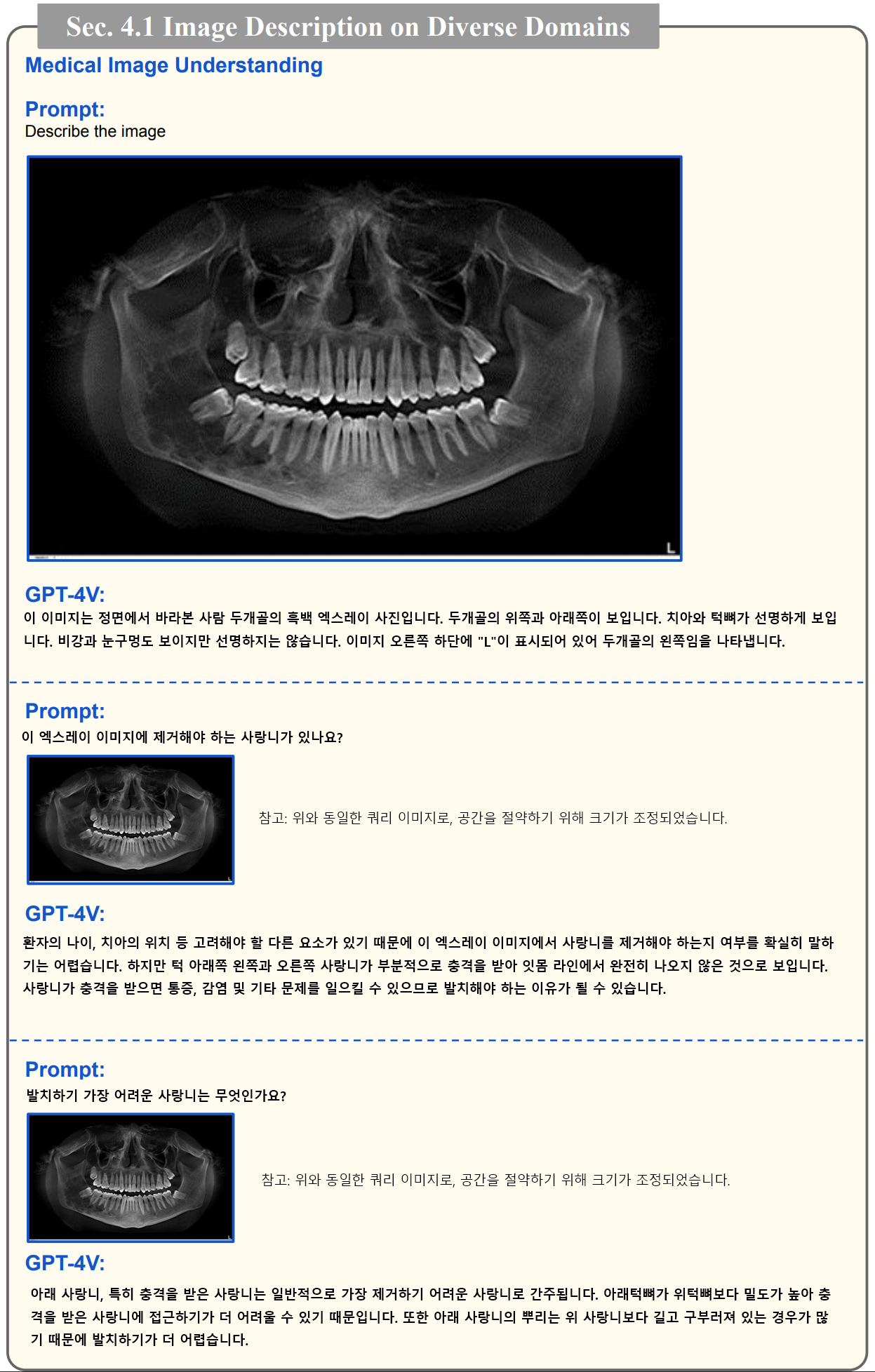
- 이 논문에서는 유명인의 인식, 랜드마크 인식, 음식 인식, 의료 이미지 인식, 의료 이미지의 이해, 장면 이해, 사실과 반대되는 예시 등을 테스트했습니다. 논문 서문에 나와 있듯이 이러한 영역은 이미 벤치마크 수준을 뛰어넘은 것으로 보입니다. 벤치마크를 위해 기존에 사람이 태깅한 것 보다 더욱 풍성한 결과를 보여주고 있기 때문이죠.

- 아래 예시에서는 사진 속 공간에 대한 이해도 하는 것으로 보입니다.
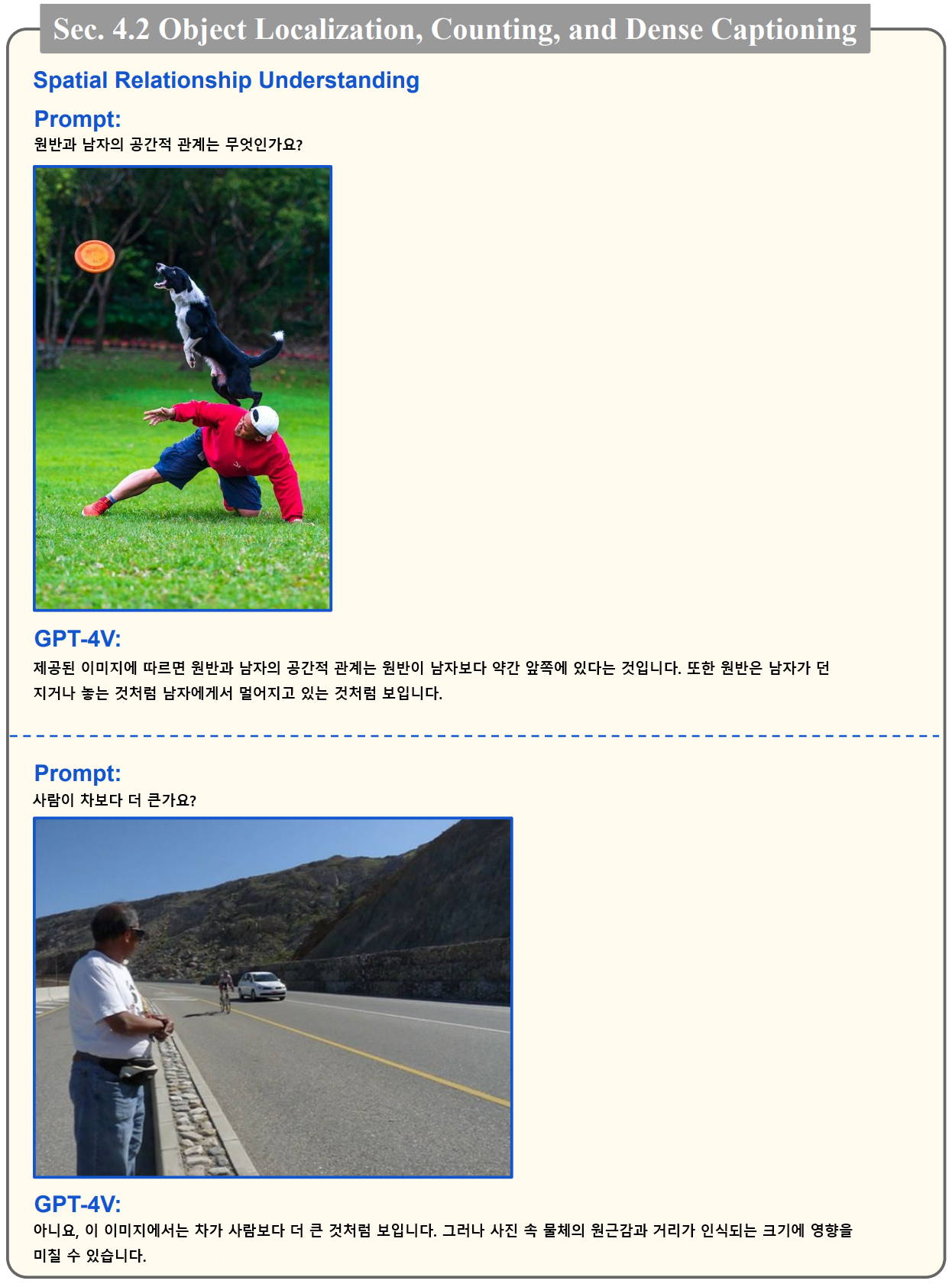
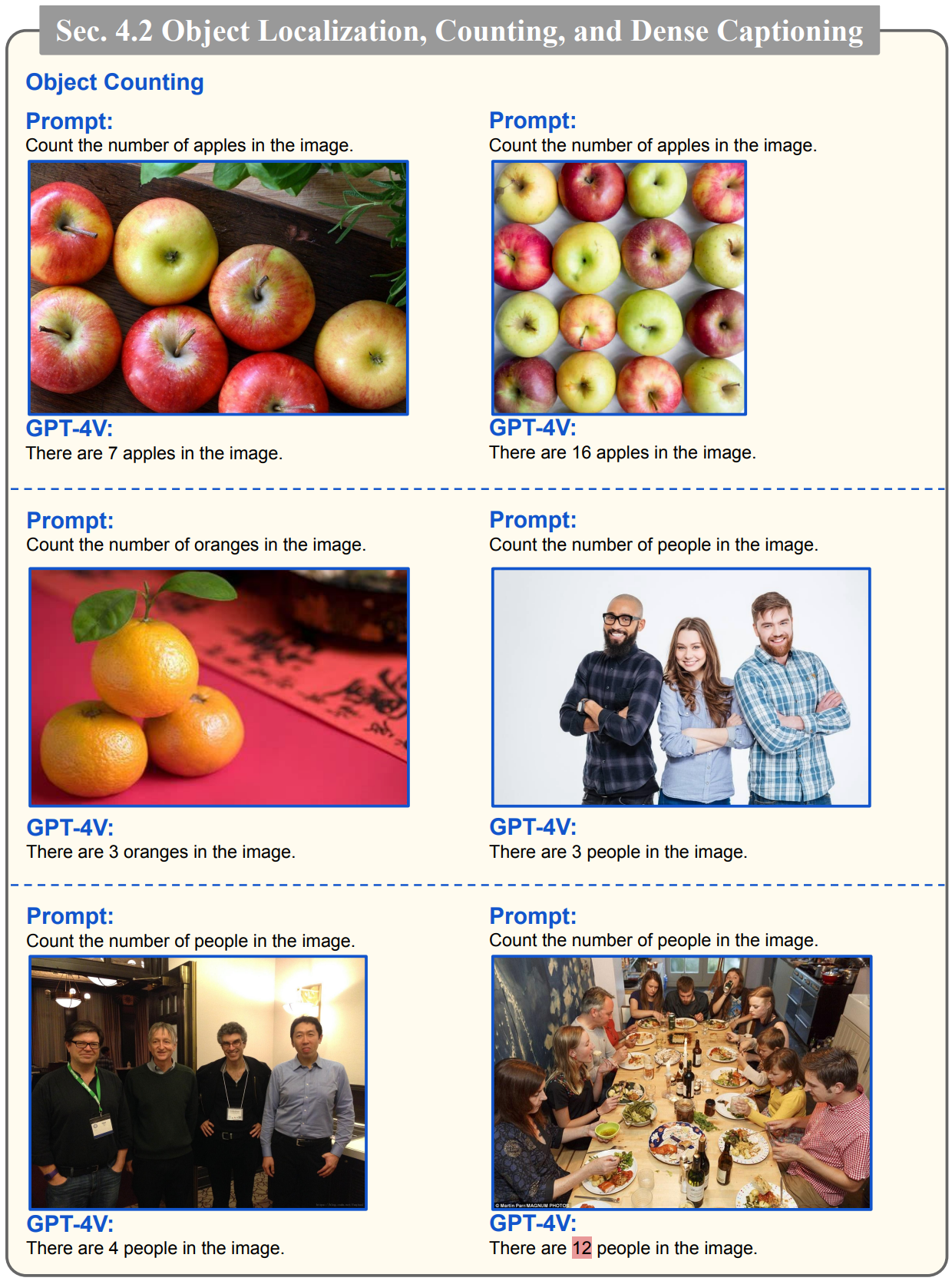
- 아래 예시에서는 이미지속 사물의 숫자를 세는 예시입니다. 마지막 사진에서 실제로는 10명이지만, 12명으로 인식하는 것을 볼 수 있는데요. 물체가 가려지거나 장면이 복잡하면 계산 과정에서 오류가 있는 것으로 보이며, 이는 프롬프트의 기법에 대한 추가 조사가 필요하다고 합니다.
- 아래 예시는 차트 이미지도 잘 인식하는 것을 보여주고 있습니다.

- 아래 예시에서는 논문을 캡쳐한 이미지도 어느정도 인식 하는 것으로 보입니다. 다만 인식에 있어 일부 오류가 눈에 띄네요.

- 아래 예시는 이미지 인식결과를 다국어로 보여주는 예시입니다.

- 뿐만 아니라 이미지 안의 텍스트에 대한 인식도 다국어를 지원합니다.
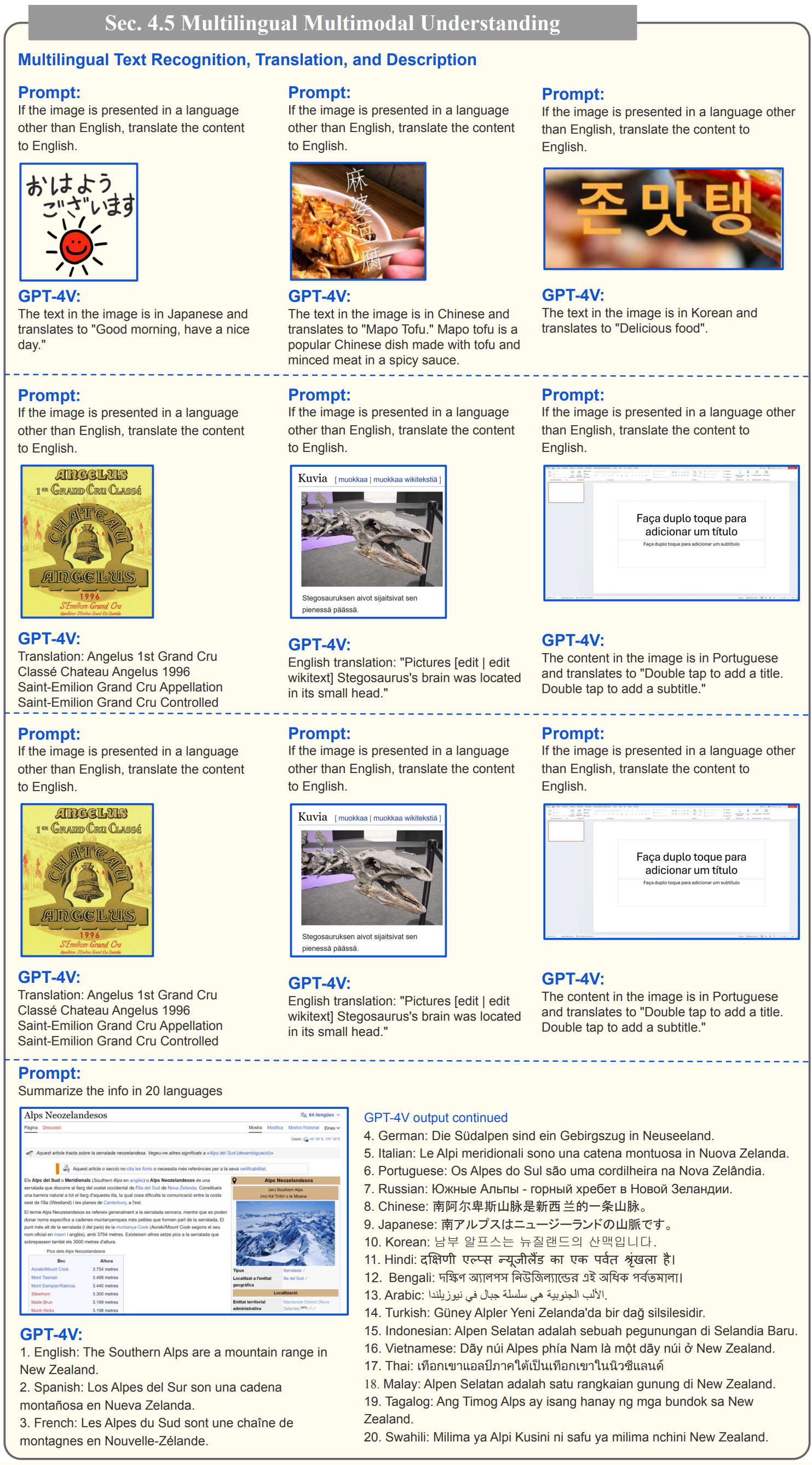
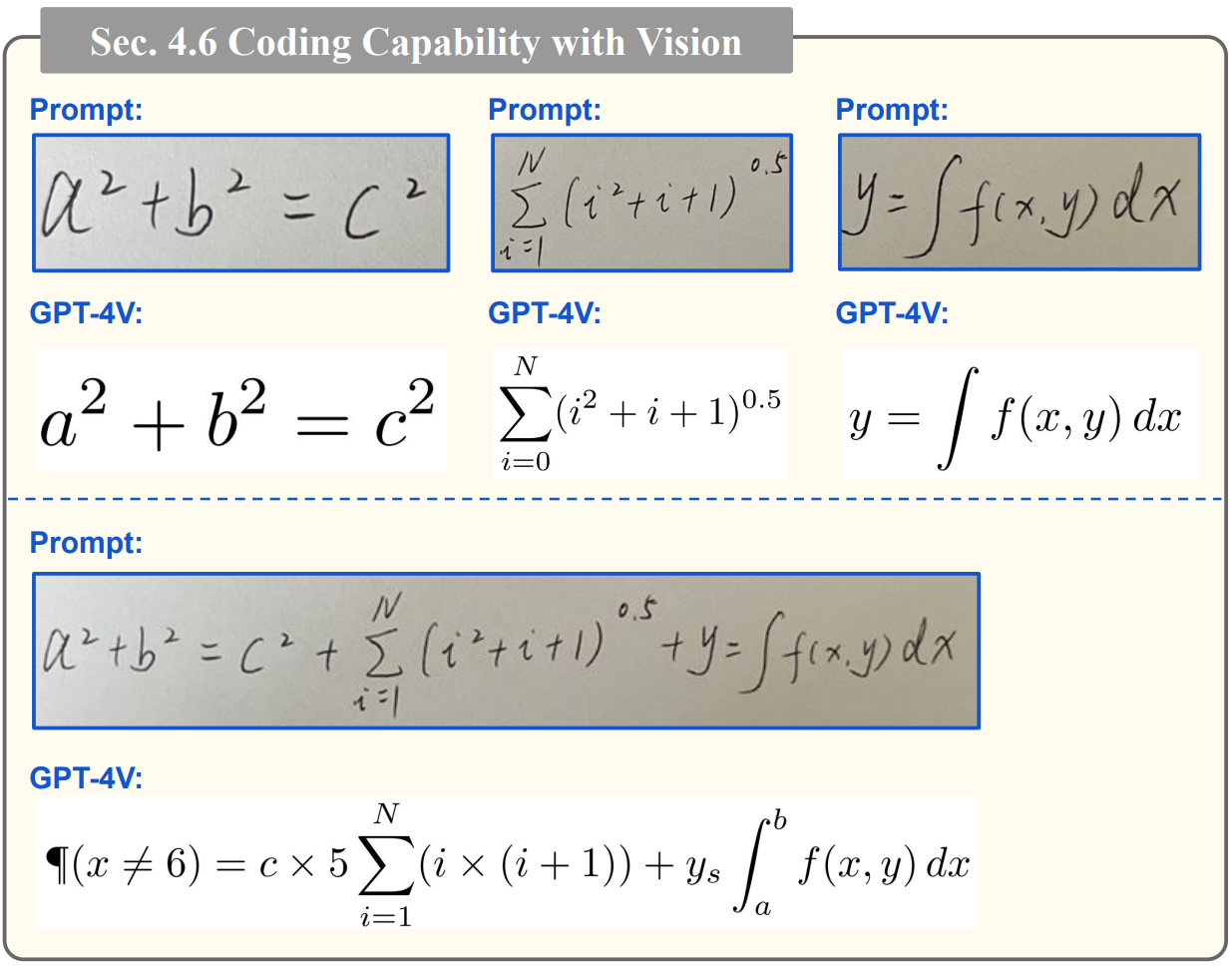
5. 멀티 이미지 시퀀싱과 비디오에 대한 이해
- GPT-4V가 비디오 프레임의 시퀀스를 정확하게 이해하고 분석할 수 있음을 보여줍니다. 이 프레임별 분석에서 GPT-4V는 활동이 일어나는 장면을 인식하여 보다 심층적인 컨텍스트 이해를 제공합니다
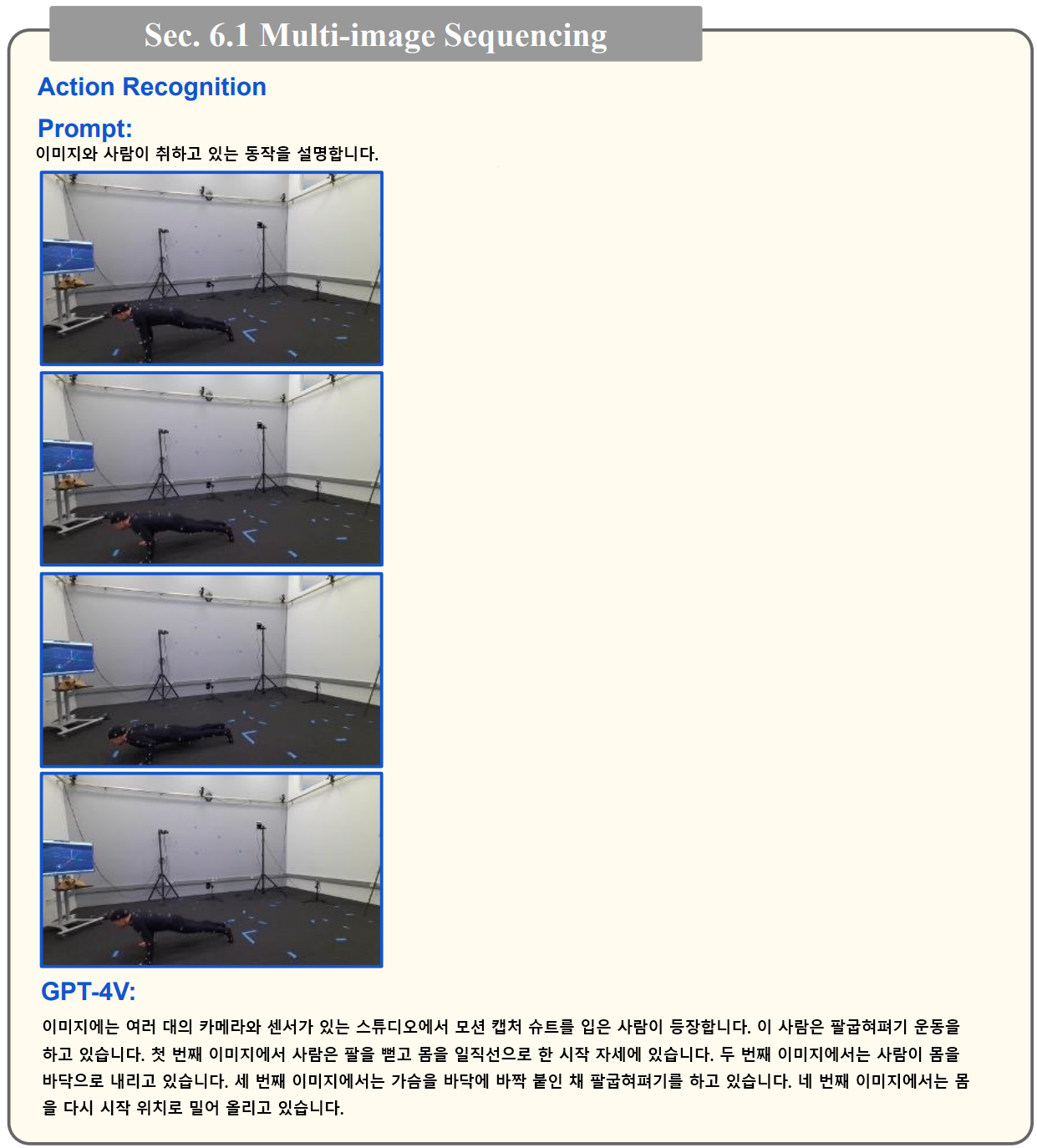
- 이 예시에서는 김밥을 만드는 주요 과정을 이미지로 제공했는데요. 시간의 순서를 섞여서 제공하고, 순서대로 이미지를 정렬하도록 한 결과 올바르게 응답을 주는 것이 확인됩니다.

- 또한 아래 예시와 같이 일련의 초기 프레임이 주어졌을 때, GPT-4V가 미래 이벤트를 예측하는 테스트도 꽤 잘 응답하는 것을 확인 할 수 있습니다. GPT-4V는 다양한 시간 구조와 복잡성을 가진 활동을 포착하고 이해할 수 있음을 알 수 있습니다.

여기까지 GPT-4V 가 할 수 있는 부분들에 대해 논문에서 제시된 사례들을 토대로 살펴보았습니다.
이후 테스트와 각 산업 영역에 활용 부분은 기회가 된다면 2부로 정리해보겠습니다.

'AI > AI 동향' 카테고리의 다른 글
| Google, GPT를 넘어선 Gemini 시대가 열렸습니다. (2) | 2023.12.07 |
|---|---|
| MistralAI - 최고의 성능까지 갖춘 최초의 Apache 2.0 라이선스 LLM 모델 등장 (0) | 2023.10.06 |
| OpenAI, 오늘부터 GPT-3.5 파인 튜닝 가능 (0) | 2023.08.23 |



